EVERY Oneworld flight marginally over 2000 miles. Your ultimate BA Tier Point Run reference! Updated 2020
When planning a British Airways Tier Point run the magical 2000 mile mark is very important as it differentiates short haul from long haul. This is the secret to getting those mega tier point run routes.
With some assistance from the Oneworld Interactive Map (searched by distance >3129km), I have tried to succinctly bunch all the routes which are classified as long haul for tier points. Please let me know if I have missed something from the list.
There is no hard and fast rule which routes over 2000 miles I have not included. I went by the general guidelines of:
- I'll mention a few cities in the general direction just over 2000 miles, e.g. Doha – Sofia which is exactly 2000 miles, but expect you to realise some city pairs roughly the same direction e.g. Doha-Milan/Rome will be longer.
- And the vague “if I didn't know there's a good chance many others didn't know either” (!)
Please also bookmark this page too. I'd hate to have spent so much time and no-one use it in the end! 😉
Contents
British Airways
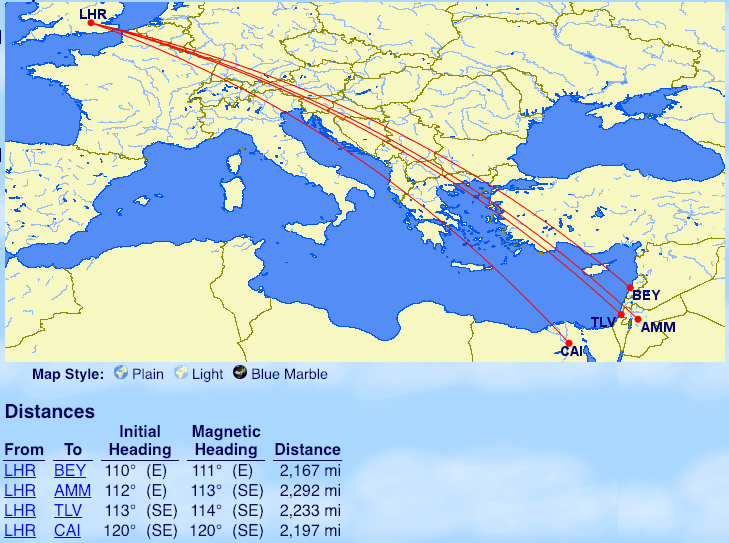
From London: Tel Aviv (TLV), Beirut (BEY), Cairo (CAI), Amman (AMM)
Notable exception: Larnaca, which is just over 2000 miles but earns 80 Tier Points in Business Class rather than 140.
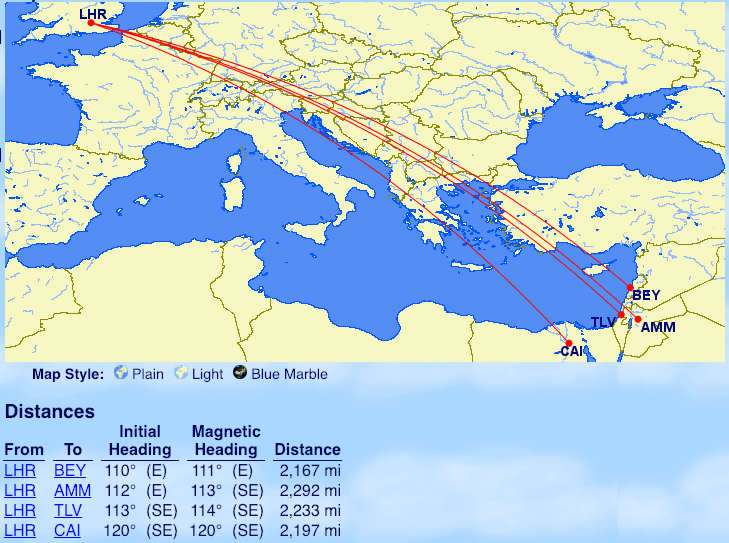
Iberia
From Madrid: Tel Aviv
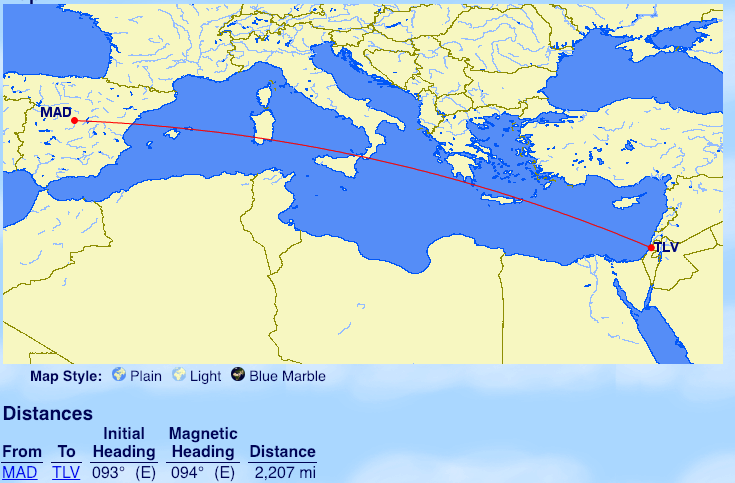
Finnair
From Helsinki: Lisbon, Malaga, Tel Aviv
LATAM (until September 2020)
From Lima: Montevideo (MVD), Rio de Janeiro, Sao Paulo, Montego Bay (MBJ), Punta Cana (PUJ), Cancun (CUN), Havana (HAV)
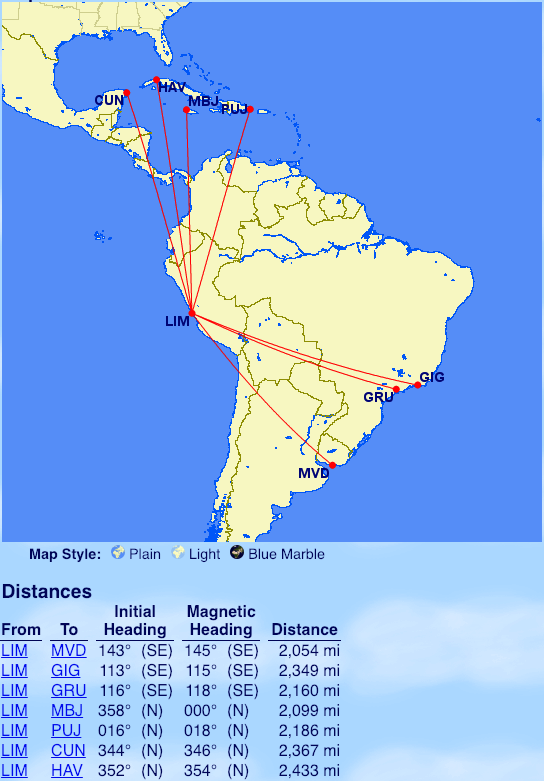
From Sao Paulo: Lima (LIM), Bogota (BOG)
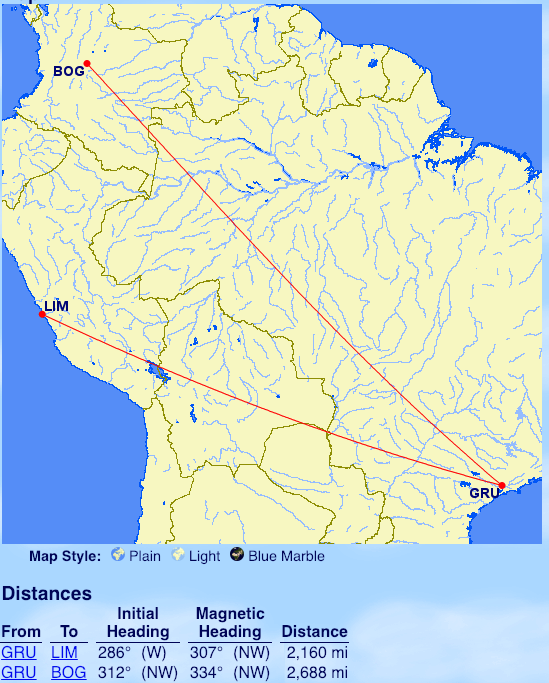
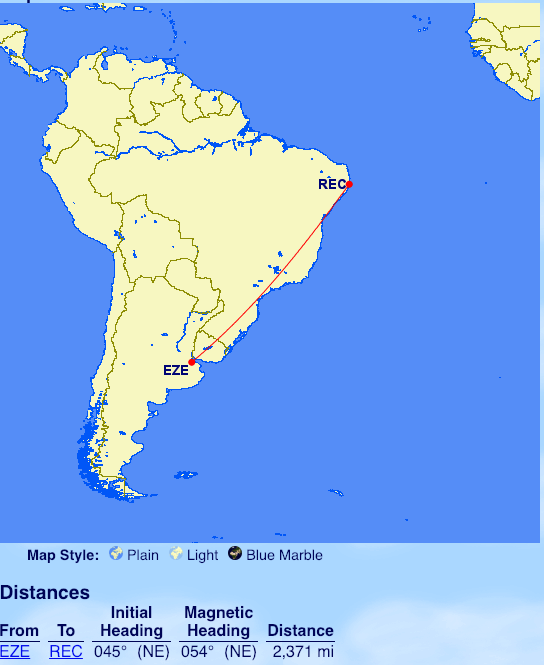
From Buenos Aires: Recife (REC)
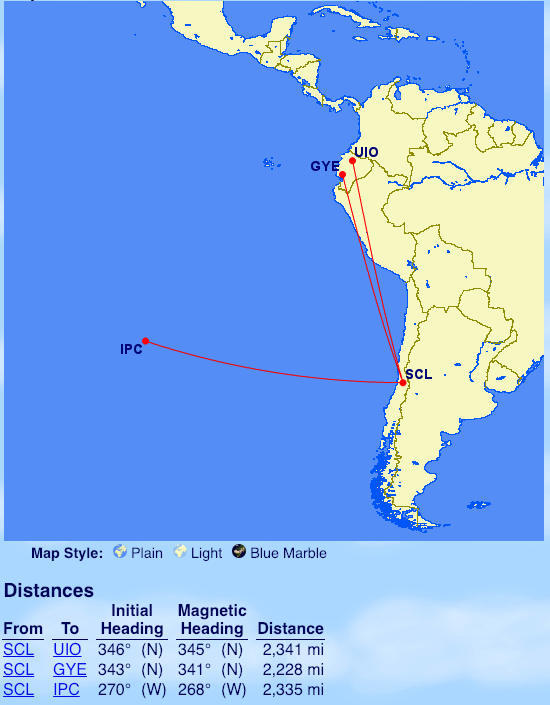
From Santiago de Chile: Guayaquil (GYE), Easter Island (IPC), Quito (UIO)
Royal Air Maroc (from 1st April 2020)
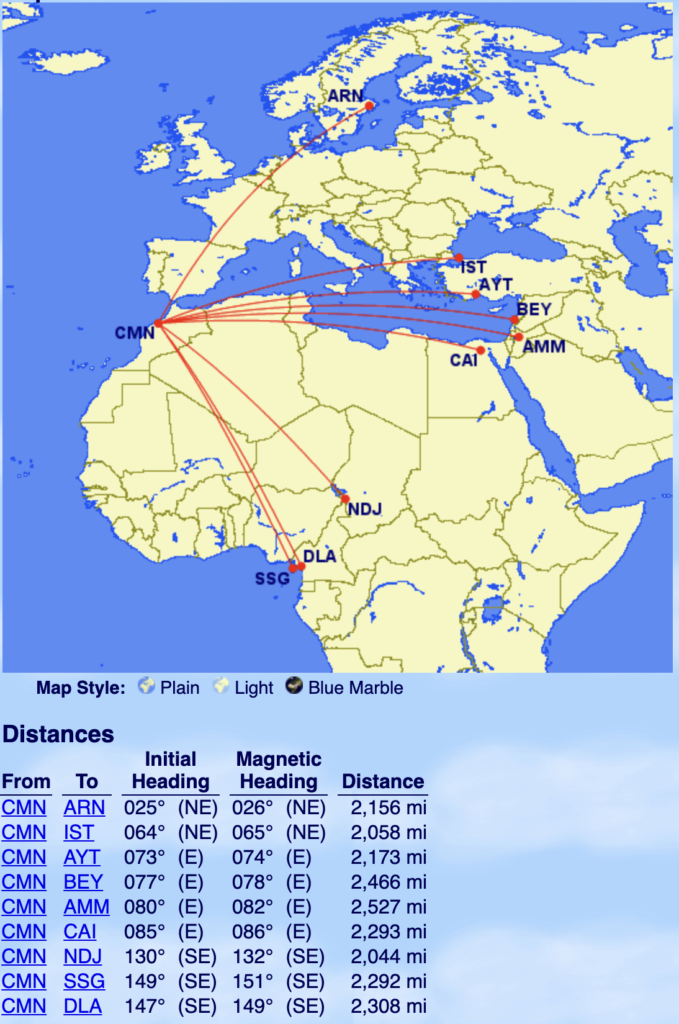
From Casablanca (CMN): Stockholm (ARN), Istanbul (IST), Antalya (AYT), Beirut (BEY), Amman (AMM), Cairo (CAI), N'Djamena (NDJ), Malabo (SSG), Douala (DLA)
Note every flight to the Middle East is over 2000 miles. Royal Air Maroc flies to several destinations there.
Also for future reference, should Royal Air Maroc ever fly to any Baltic states or other Northern Scandinavian destinations, these would also qualify. For reference Casablanca-Oslo is 2038 miles and Casablanca-Vilnius (the most southerly of Baltic states) is 2165 miles.
Royal Jordanian
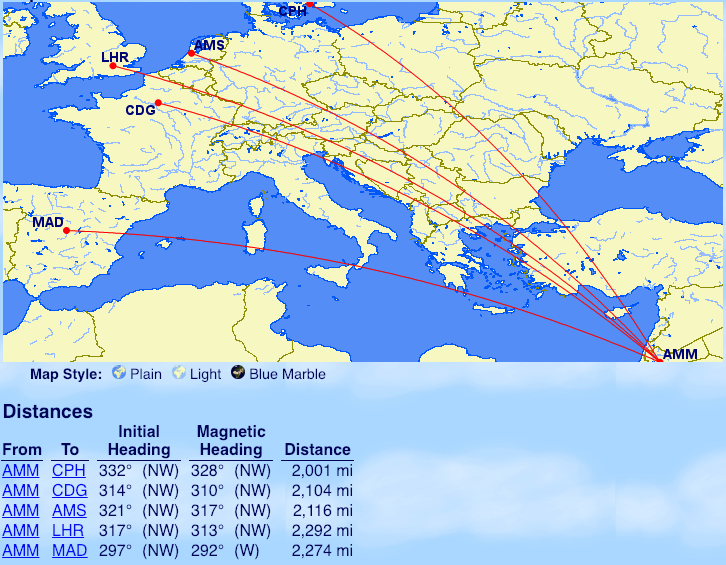
From Amman (AMM): Copenhagen (CPH), Paris (CDG), Amsterdam (AMS), Madrid (MAD), London (LHR)
American Airlines
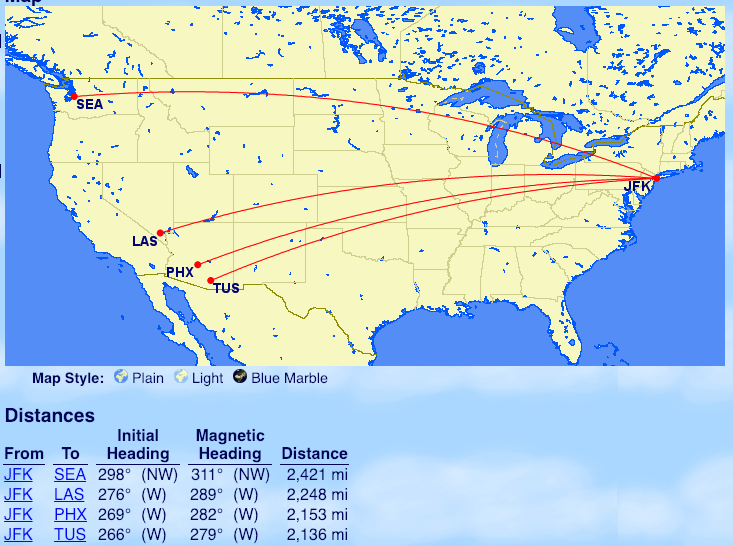
From New York (JFK): Seattle (SEA), Las Vegas (LAS), Phoenix (PHX), Tucson (TUS)
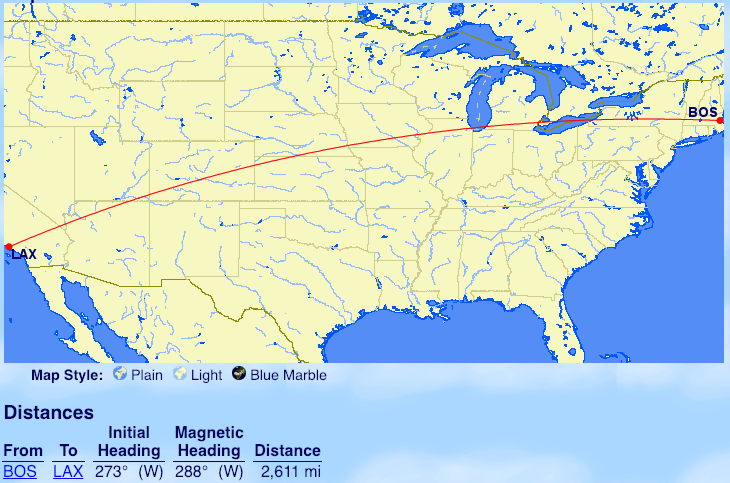
From Boston: Los Angeles (LAX),
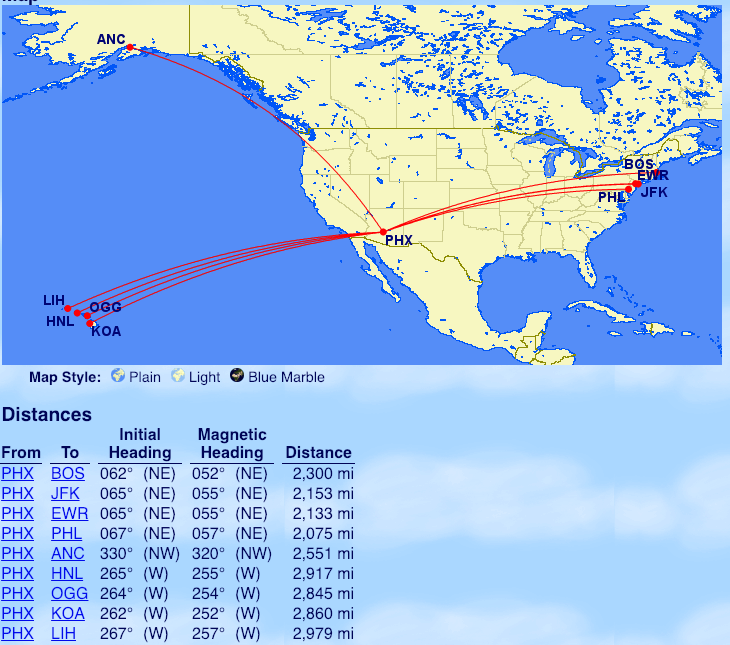
From Phoenix: Boston (BOS), New York (JFK, EWR), Philadelphia (PHL), Anchorage (ANC), Hawaii (HNL, OGG, KOA, LIH)
From Miami: Las Vegas (LAS), Los Angeles (LAX)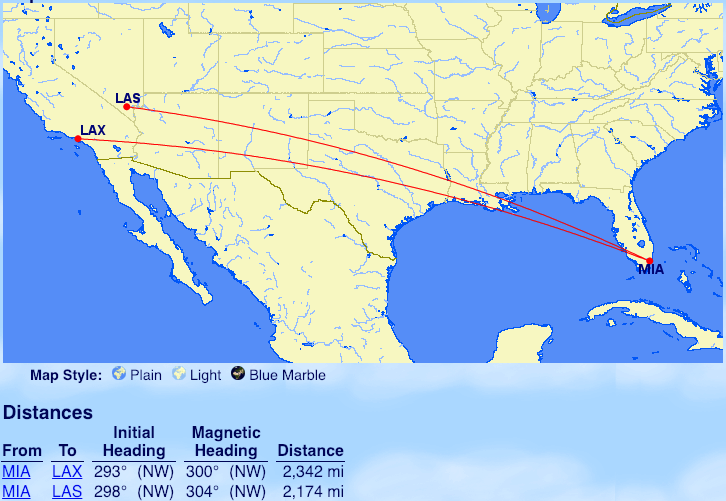
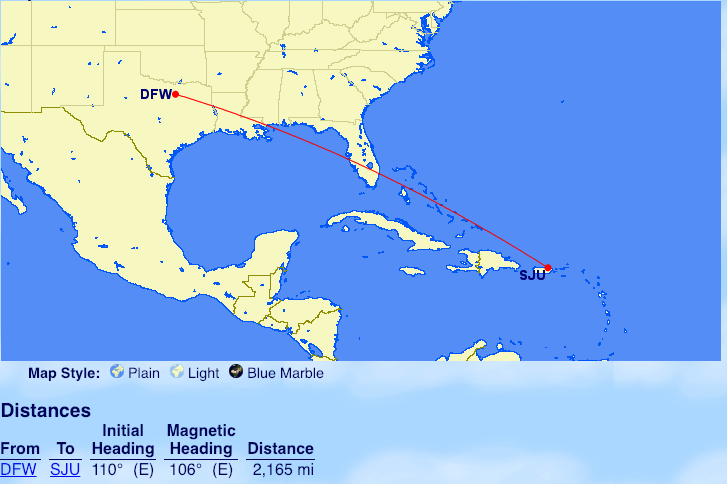
From Dallas – Fort Worth: San Juan (SJU)
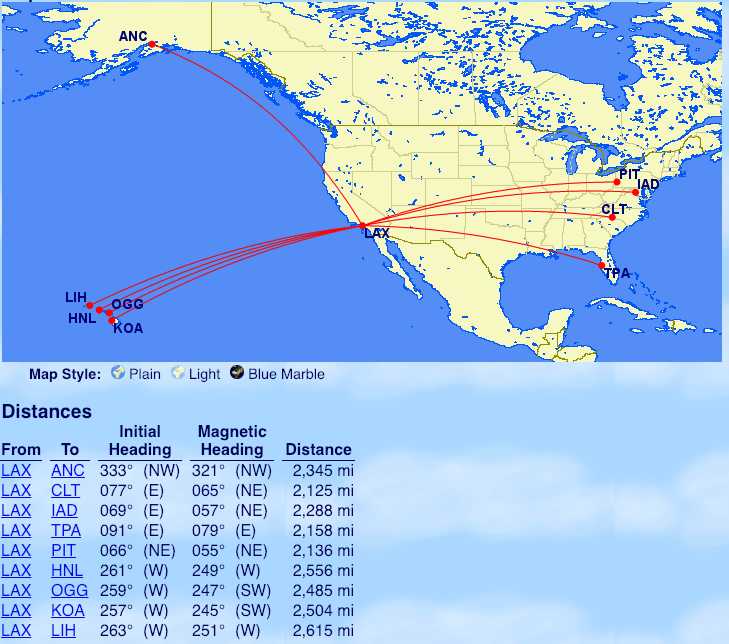
From Los Angeles: Anchorage (ANC), Charlotte (CLT), Washington Dulles (IAD), Tampa (TPA), Pittsburgh (PIT), Hawaii (HNL, OGG, KOA, LIH)
Japan Airlines
From Tokyo (NRT): Hanoi
Note nearly every other international flight is under 2000 miles, or very well clear of 2000 miles.
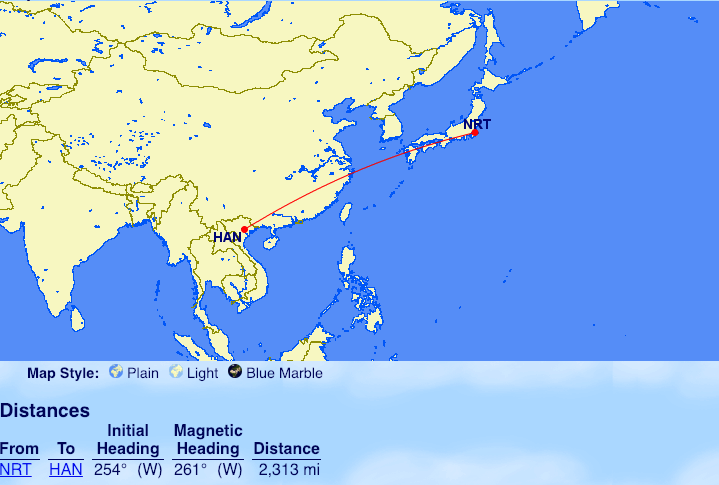
Qantas
From Sydney: Perth (PER), Broome (BME)
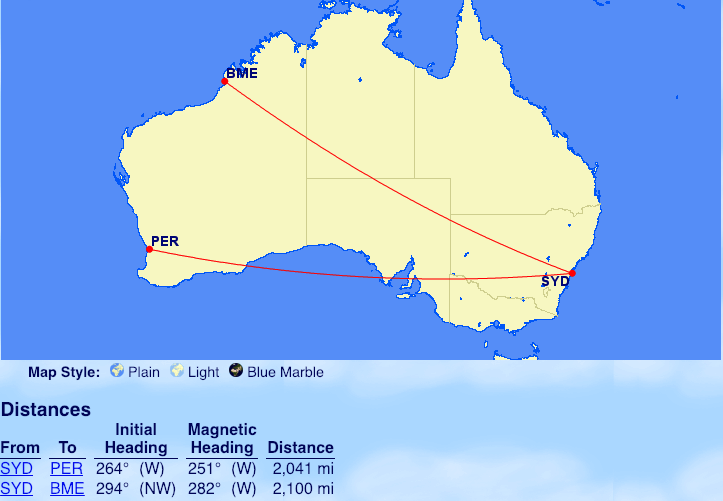
From Brisbane (BNE): Broome (BME), Port Hedland (PHE), Perth (PER)
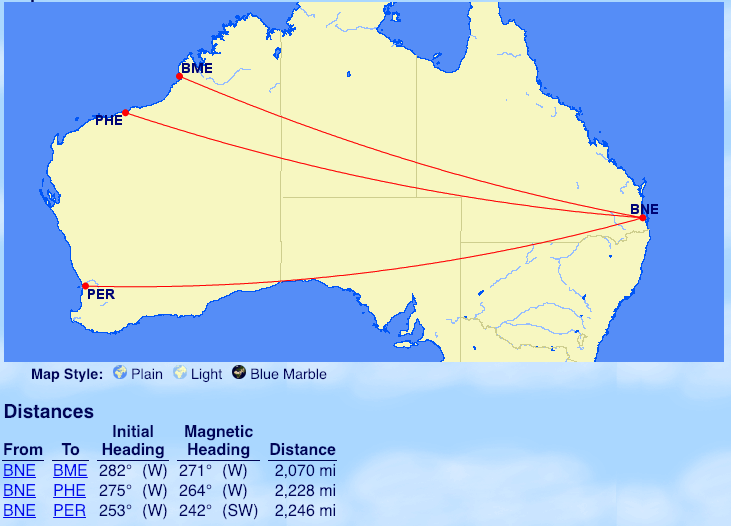
From Perth (PER): Sydney (SYD), Brisbane (BNE), Singapore (SIN)
Note just about any non-New Zealand international flight out of Melbourne and Canberra are over 2000 miles.
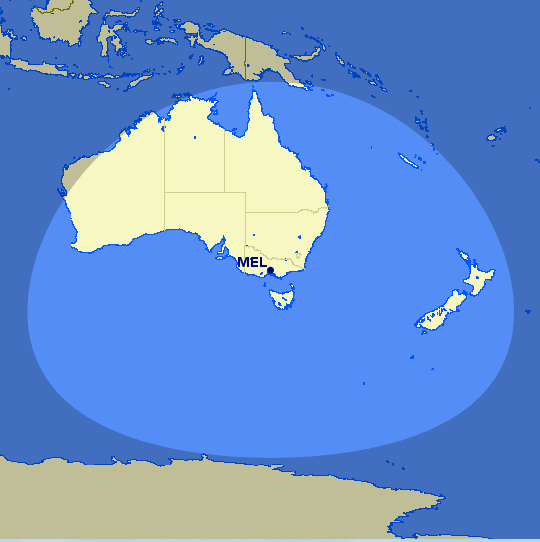
Qatar Airways
From Doha: Belgrade (BEG), Sarajevo (SJJ), Moscow (DME), Sofia (SOF), Thiruvananthapuram (TRV), Chennai (MAA), Kiev (KBP), Male (MLE), Skopje (SKP), Nairobi (NBO), Mombasa (MBA), Seychelles, Kathmandu (KTM), Entebbe (EBB), Kilimanjaro (JRO), Colombo (CMB)
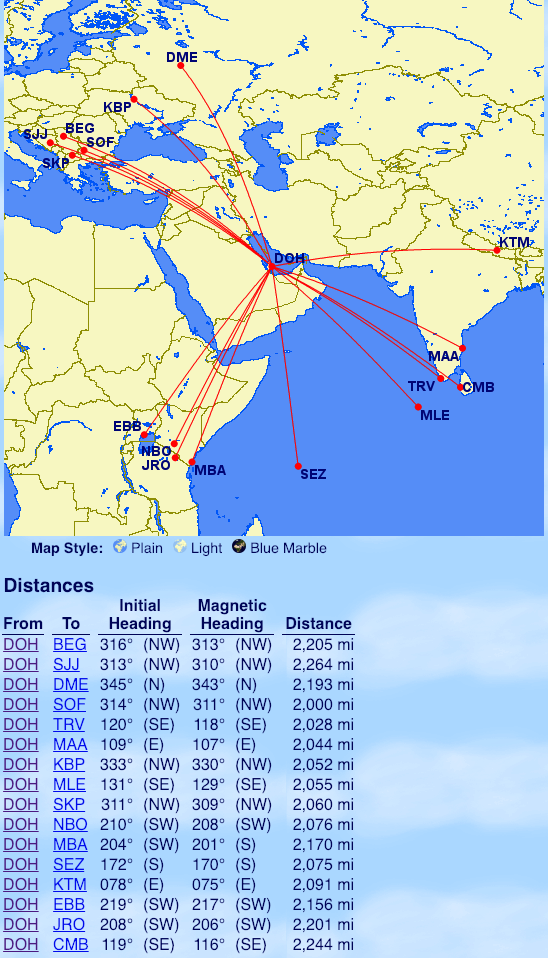
Cathay Pacific
From Hong Kong: Jakarta (CGK), Denpasar (DPS), Surabaya (SUB), Sapporo (CTS)
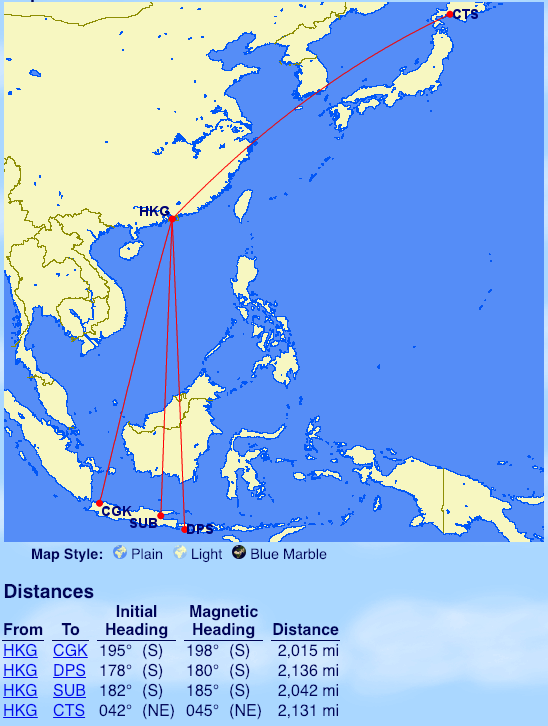
Malaysia Airlines
From Kuala Lumpur: Taipei (TPE), Kathmandu (KTM), Mumbai (BOM), Delhi (DEL), Nanjing (NKG), Shanghai (PVG), Perth (PER)
From Kota Kinabalu (BKI): Tokyo (NRT), Perth (PER)
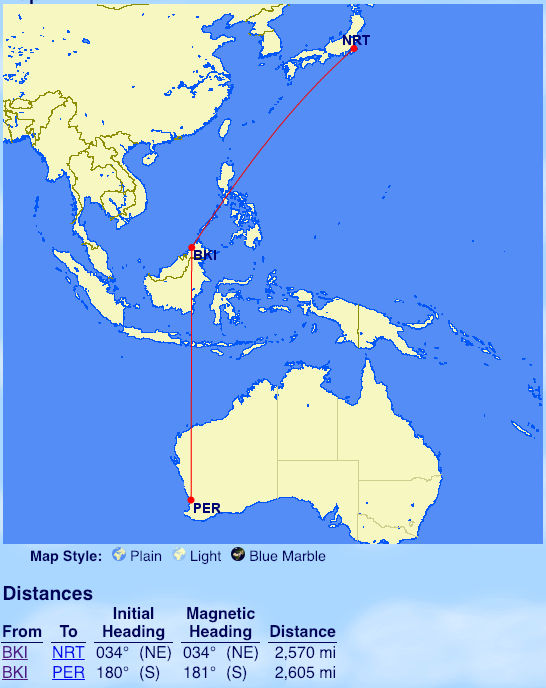
Sri Lankan Airlines
From Colombo (CMB): Dammam(DMM), Bahrain (BAH), Doha (DOH), Dubai (DXB) Abu Dhabi (AUH), Jakarta (CGK)
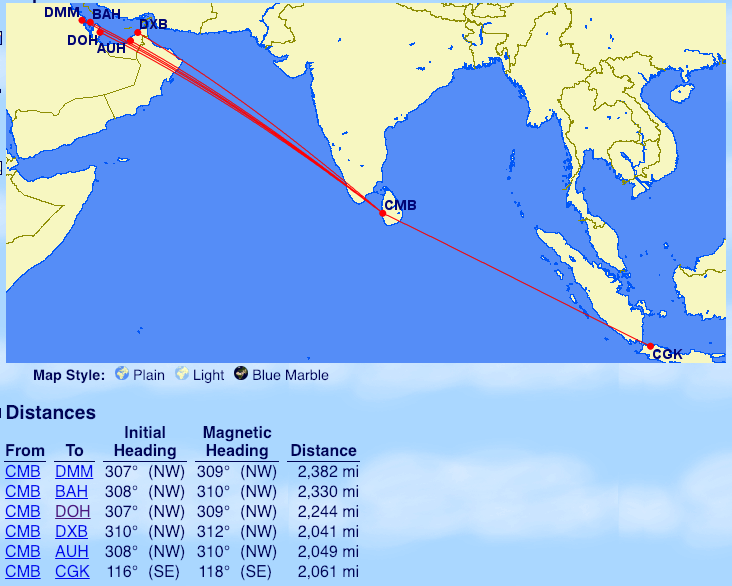
S7
To try and help distinguish, domestic flights are in italics.
From Moscow (DME): Malaga (AGP), Alicante (ALC), Valencia (VLC), Ibiza (IBZ), Reykjavik (KEF), Tenerife South (TFS), Urumqi (URC) Krasnoyarsk (KJA), Abakan (ABA), Bratsk (BTK)
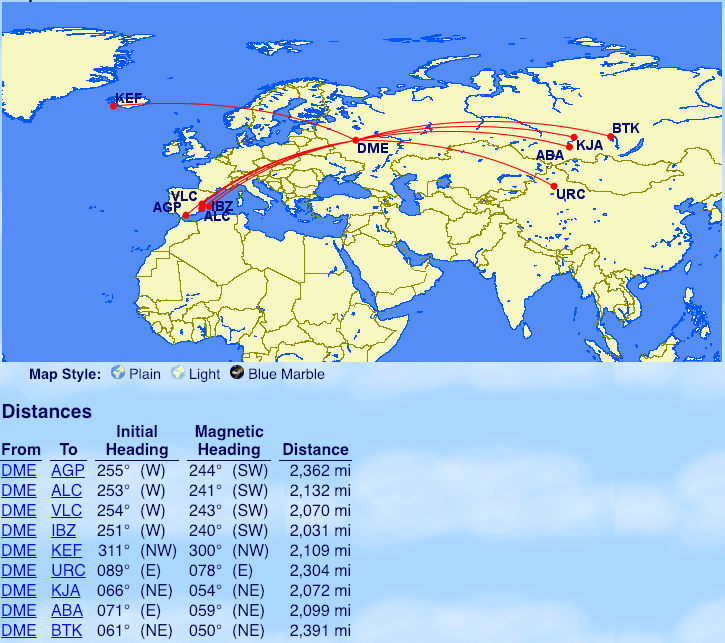
From St. Petersburg (LED): Alicante (ALC)
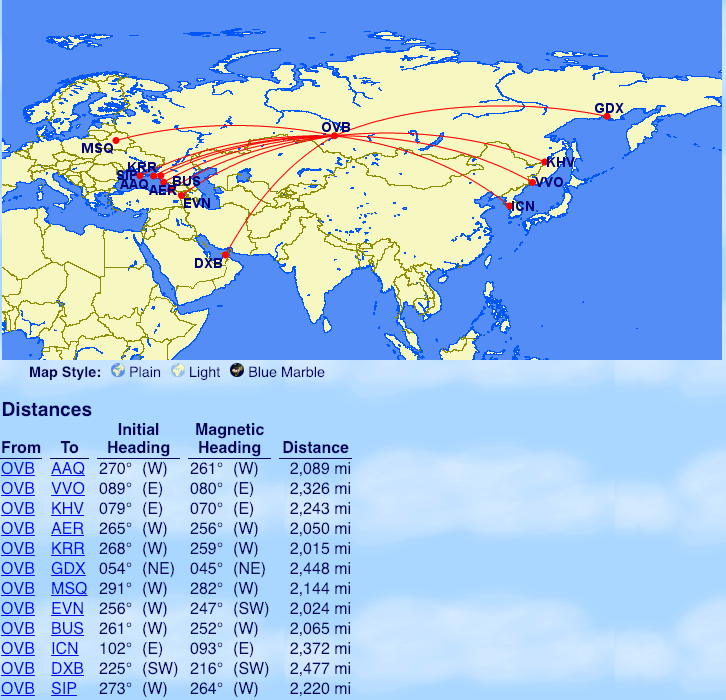
From Novosibirsk (OVB): Anapa (AAQ) Vladivostok (VVO), Khabarovsk (KHV), Sochi (AER), Krasnodar (KRR), Magadan (GDX), Minsk (MSQ – Belarus), Simferopol (SIP – Ukraine), Yerevan (EVN – Armenia), Batumi (BUS – Georgia), Seoul (ICN), Dubai (DXB)
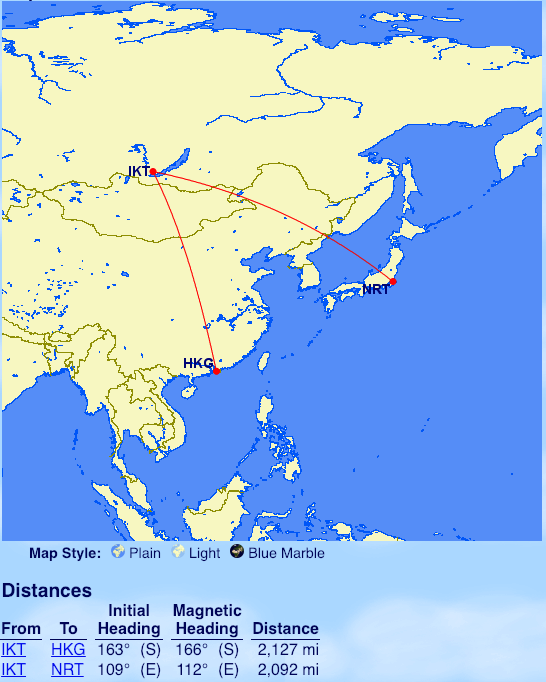
From Irkutsk (IKT): Hong Kong (HKG), Tokyo (NRT)
Never been able to get 140 in Qantas from Sydney to Perth?
Brisbane Perth, no problem
Am I missing something?
It’s 140TP
Qatar: doh-bud 2335, doh-zag 2419, etc…
Too many QR route to Europe. Just the ones to East Europe are sufficient for this list.
“Please also bookmark this page too. I’d hate to have spent so much time and no-one use it in the end! ”
Thanks for this. I have bookmarked it 🙂
Thank you very much!
Same here… Great resource
This is fantastic, thank you! Bookmarked 🙂
Thank you!
Nice work; really! Now what may would appreciate (given American Airlines’ current trajectory) is a companion post outlining the best ways to earn OneWorld Emerald status via British Airways rather than chasing AA’s Executive Platinum status any longer.
A lot of it is answered in this post, (https://pointstobemade.boardingarea.com/2019/01/11/ba-tier-point-runs/) but I’ll try to do a post to outline reasons why AAdvantage members should go BAEC instead. Thanks for the idea!
Juste one word amazing.
Thank you!
Great work. Thank you….safely bookmarked.
Thank you!
Simply amazing. Good work!
I found KUL-ICN on Malaysian to be over 2.000 as well.
Thanks! I knew about this but did not add it because it is quite far over 2000 miles. KUL-TPE is already in that general direction and more marginal.
I reference this article still.
LAX—CLE is 2052 miles also
Thank you! I’ll add this to the next update
I am looking to go to LA with a trip to Hawaii and want to make the most of increasing as much tier points as possible on this trip.
What is the most efficient way to do this?
Fly American Airlines domestic first class and make as many connections as you can. You will probably be governed by specific routing rules though, so your best best is just to find a reasonably priced ticket with with loads of connections.
Thank you. I forgot I will be departing from LHR.
hello
what is the best way to go to South Korea.
I will depart from LHR
gary
If ‘best’ means getting as many TP as you can, then LHR->KUL->ICN
Thank you. Excellent quick reference
Thanks for the work. Will you update with Royal Air Maroc ? It would be a great 560 TP run from ARN via Morocco to Brasil….however it seems until today RAM is not offering such a routing with transfer in Morocco…let´s see what the future brings.
Hi! Yes I will include RAM, already started investigating their routes
Wow. This is phenomenally useful! Bookmarked with many thanks.
Thank you!
Berlin Doha On Qatar is a great starting point too. And very cost-effective as well.
Absolutely! I didn’t mention Berlin because it’s very well clear of 2000 miles, but it regularly shows up on QR sales
Really useful post. Under AA, i find routes such as CLT-LAX/SFO, BOS-LAX/SFO very useful as well – all over the magic 2000 mile mark
Tim, I’m in YVR. What is the best way and which fare should I consider buying to maximize my £:TP ratio to PVG, PEK, TYO, TPE, and HKG?
Thank you.
LHR -> AMM/CAI is now only 80 per segment rather than 140.